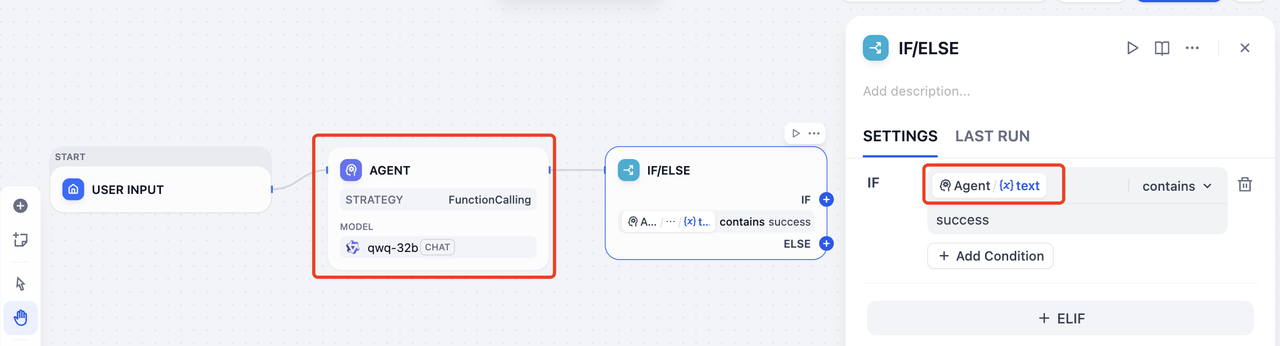
示例:IF/ELSE 节点只能从文本里推断状态。
靠判断 Agent 有没有说出 success,既脆弱,也难维护。
原始表格、报告或中间文件可能埋在记忆里,下游只看得到总结。
后一个 Agent 不能稳定知道前一个 Agent 究竟交付了什么。
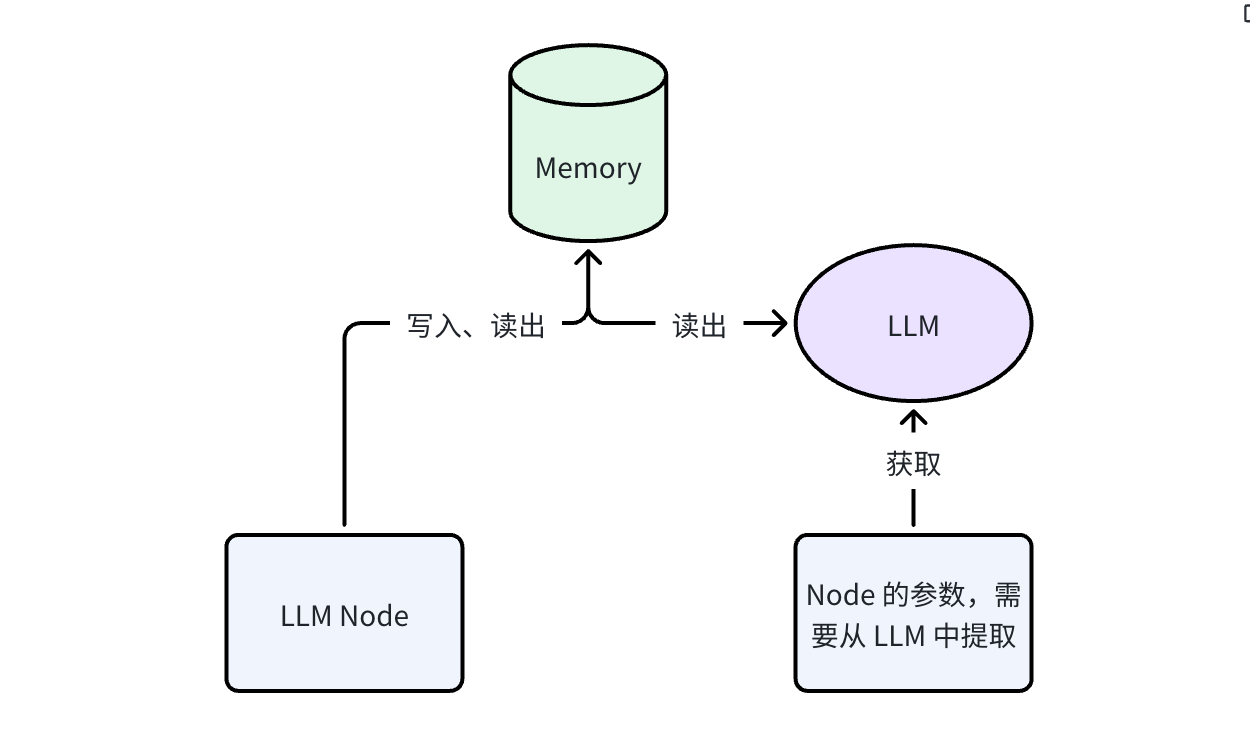
提取 LLM 调用很轻量:读取有界上下文窗口,输出结构化字段。典型开销 <1s、<500 tokens。
如果提取失败,节点回退到上游 Agent 的原始文本输出,工作流不会静默中断。
RAG 从外部语料库检索;Memory Extraction 从同一次运行的工作上下文中提取。无需向量库 —— 这是工作流内状态,不是跨会话检索。

