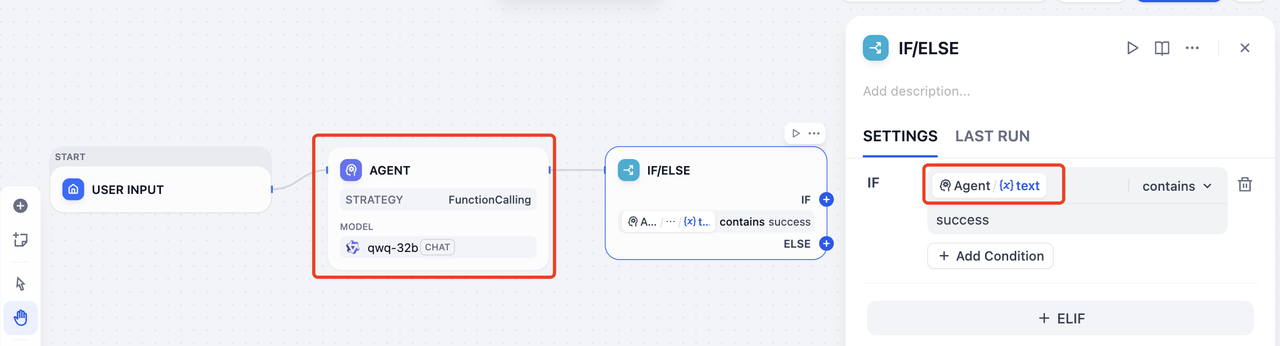
Example: an IF/ELSE node tries to infer state from plain text.
Checking whether the agent happened to say success is brittle and hard to maintain.
Raw tables, reports, or generated artifacts can stay buried in memory while the next node only sees the summary.
The next agent cannot reliably see what the previous one actually delivered.
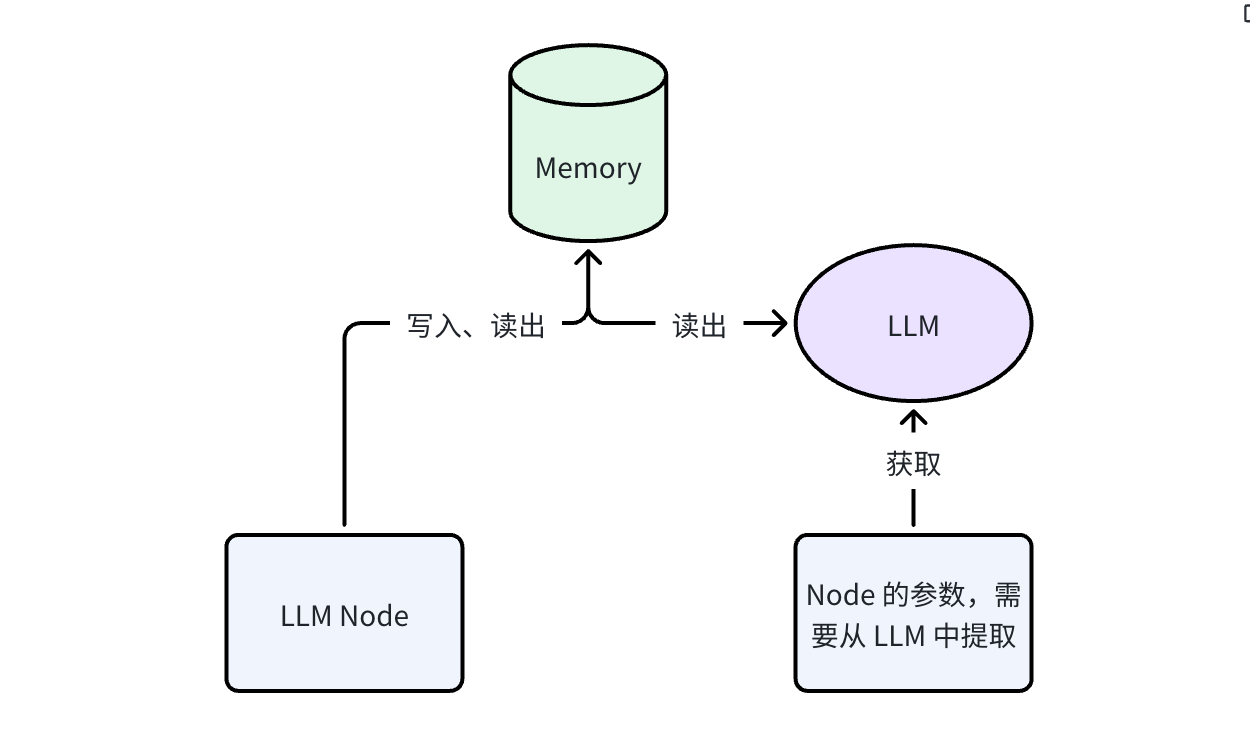
The extraction LLM call is lightweight: it reads a bounded context window and outputs structured fields. Typical overhead is <1s and <500 tokens.
If extraction fails, the node falls back to the upstream agent's raw text output, so the workflow never silently breaks.
RAG retrieves from an external corpus; Memory Extraction pulls from the same run's working context. No vector DB needed — this is intra-workflow state, not cross-session retrieval.

